Hvorfor et Telugu-tegn bricker Apple-enheder
Apple har haft en buggy få måneder. Nu har vi fået en ny, alvorlig fejl i tekstgengivelsesfunktionaliteten i iPhones. Fejlen udløses af en enkelt Telugu karakter, der kan forårsage, at en iPhone går ind i en ubrydelig opstartssløjfe bare ved at modtage en meddelelse, der indeholder tegnet. Lad os dvæle på, hvorfor en enkelt karakter kan forårsage sådanne store problemer med iOS.
Bemærk: En løsning til Telugu-fejlen er tilgængelig i den nyeste version af iOS (11.2.6). Hvis Telugu-tegnet har låst din app eller enhed, skal du gendanne din iPhone via iTunes og opdatere til den nyeste version af iOS. Hvis din iPhone sidder fast i en opstartssløjfe, skal du muligvis sætte den i DFU-tilstanden (Device Firmware Update) for at få iTunes til at genkende det. Når du er færdig, skal du gendanne din enhed fra din seneste backup, som du forhåbentlig har oprettet.
Hvad er telugu?

Telugu er et sprog, der tales og skrives i dele af Indien, specielt staterne Andhra Pradesh, Telangana og i byen Yanam. Som mange script-baserede sprog, såsom arabiske og andre Brahmic-scripts, bruger Telugu nogle specielle funktioner i Unicode-tegnsættet til at vise sine tegn på en computerskærm.
Mens de fleste latinske bogstaver er repræsenteret af et enkelt 8-bit Unicode-kodepunkt for ASCII-kompatibilitet (for eksempel findes bogstavet A ved Unicode-kodepunktet U+0041, som er repræsenteret binært senest 01000001 ), sprog skrevet med script eller ikke- Latinske bogstaver kombinerer typisk mere end et Unicode-kodepunkt, der repræsenterer deres tegn.
Dette gælder især for sprog som telugu, som kombinerer sprogernes versioner af bogstaver i klynger. I modsætning til engelsks stilistiske ligaturer er forbindelsen mellem hver Telugu-bogstav lingvistisk vigtig. For at imødekomme dette indbefatter Unicode et komplekst system til at vedhæfte tegn, hver repræsenteret ved deres eget kodepunkt, til hinanden.
I betragtning af det rene antal Unicode-kodepoint kan dette skabe næsten uendelig variation. Disse punkter kombineres for at gøre en læselig karakter. På denne måde behøver Unicode ikke et Unicode-kodepunkt for bogstaveligt talt ethvert Telugu-ord. I stedet kombinerer Unicode Telugu-konsonanter, vokaler og diacritics ("virama") sammen for at skabe ord, der vises som en enkelt karakter. Det samme gælder for andre sprog med ortografiske regler for ligaturer, som arabisk.
Hvad forårsager nedbruddet?

Problemet synes at være relateret til Zero Width Non-Joiner (ZWNJ) ved kodepunkt U+200C . ZWNJ anmoder om, at to tilstødende tegn gør uden deres typiske ligatur. På engelsk holder en ZWNJ tegnene ff fra at blive udskrevet med deres standardforbindelsesligatur, i stedet adskiller hver f. Men når det kombineres med et bestemt sæt af fire Telugu-kodepunkter (som alle skal kombinere til en enkelt klynge), kan iOS af en eller anden grund ikke vise resultatet korrekt.
Nogle har spekuleret på, at Apples San Francisco-skrifttype ikke kan vise tegnet, mens andre har sagt, at den specifikke gengivelsesproces, Apple anvender, er skylden. Uanset den nøjagtige årsag forårsager forsøget på at gøre karakteren et dramatisk nedbrud af uanset hvad der gør det, fra Meddelelser og WhatsApp til Springboard. Unicode-koden punkter, der udgør karakteren ("gya" betyder "viden") er under:
U+0C1Cja (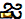 )
)U+0C4DetU+0C4Deller diakritisk mærke ( )
)U+0C1Enya (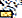 )
)U+200Cnul bredde non-joinersU+0C3Eaa (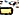 )
)
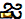 )
) )
) )
) )
)Men vi kan ikke engang bebrejde Zero Width Non-Joiner (ZWNJ) alene. Det bruges også i den uskyldige familie emojis (????) Uden noget problem. Det ser ud til at være en bestemt kombination af nogle specifikke kodepunkter og ZWNJ. Hvis man tilføjer skade til skade, ser det ud til, at ZWNJ heller ikke har nogen særlig effekt på gengivelsen på denne telugu-klynge, eller at den ikke engang skal være der i første omgang.
Andre Brahmic Script Problemer
Telugu er dog ikke det eneste sprog med dette problem. Bengali og Devanagari, som bruger Unicode på samme måde for deres Brahmic-scripts, har det samme problem. Manish Goregaokar skriver et fasctinerende og detaljeret blogpost, der bryder den præcise nedbrudssag ned endnu længere:
Enhver sekvens
i Devanagari, Bengali og Telugu, hvor:1.
consonant2er suffix-sammenføjning (pstf/vatu)
2. Consonant1 er ikke et reph-dannende brev
3.vowelhar ikke to glyph komponenter
Konklusion: Hvorfor blev dette ikke fanget af Apple?
For at forstå, hvordan denne fejl kom igennem, skal du sætte dig selv i Apples sko. Sikker på, denne tegnkombination er ikke noget super uklart ord på telugu-sproget. Men iPhonen indeholder støtte til snesevis af sprog. Der er bogstaveligt talt milliarder potentielle kombinationer i Unicode. Med den store variation vil meningsfuld testning af Unicode-fejl før en udgivelse gøre det umuligt at lave regelmæssige softwareopdateringer.
Fejlen burde dog ikke have forårsaget så meget skade. Telefoner bør ikke få mursten baseret på indholdet af en tekstbesked. Mens eftersyn er helt sikkert 20/20, ser det ud som om at gøre tegnet som et spørgsmålstegnkasse ( ) ville have været bedre end at køre Springboard.

![Hvordan man laver smarte postkasser leverer [Mac]](http://moc9.com/img/smartmail-spotstation.jpg)



